
如今的产品变得愈发智能,力图为使用者提供额外价值。 为了优化其使用,智能用品需要了解它们的环境。 人工智能可以解密来自各种传感器(如加速度计或麦克风)的数据,使这些数据对人类有意义。 例如,我们教会了一个神经网络如何区分场景(室内、室外、车内),以便能够根据用户所处环境优化设备行为。 经过STM32Cube.AI优化后,AI模型可以在超低功耗微控制器上运行,方便在各种产品中嵌入智能。 通过用新数据重新训练AI模型,此方法可以轻松应用于许多其他用例或环境。
方法
声学场景分类 (ASC) 的目标是将实际环境分为三个预定义类别(室内、室外、车内),这些类别的声学特征由单个数字麦克风进行捕获。 演示在一个小型板载SensorTile上运行,通过蓝牙低功耗与智能手机应用程序连接。
我们使用 FP-AI-SENSING1功能包构建了这个示例,并在 STEVAL-STLKT01 V1电路板上运行。 ASC配置以16 kHz(16位,1通道)的速率使用板载MEMS麦克风捕获音频。 每毫秒都会接收到一个DMA中断,其中包含最后的16个PCM音频样本。 这些样本将在滑动窗口中累积,该窗口包含1024个样本,具有50%的重叠。 每累积512个样本(即32毫秒),缓冲区就将注入ASC预处理,以进行特征提取。 ASC预处理将音频特征提取到LogMel (30×32) 声谱图中。
为了计算效率和内存管理优化,该步骤被划分为两个程序:
每1024毫秒,将 (30×32) LogMel声谱图输入到ASC卷积神经网络输入,然后可以将输出标签分类为室内、室外和车内。
我们使用 FP-AI-SENSING1功能包构建了这个示例,并在 STEVAL-STLKT01 V1电路板上运行。 ASC配置以16 kHz(16位,1通道)的速率使用板载MEMS麦克风捕获音频。 每毫秒都会接收到一个DMA中断,其中包含最后的16个PCM音频样本。 这些样本将在滑动窗口中累积,该窗口包含1024个样本,具有50%的重叠。 每累积512个样本(即32毫秒),缓冲区就将注入ASC预处理,以进行特征提取。 ASC预处理将音频特征提取到LogMel (30×32) 声谱图中。
为了计算效率和内存管理优化,该步骤被划分为两个程序:
- 第一部分利用 FFT 和滤波器组应用软件(30 个梅尔频段),将时域输入信号转换为梅尔音阶,计算出 32 个频谱图列中的一个。
- 第二部分,在计算完所有 32 列后(即 1024 毫秒后),对熔融缩放频谱图进行对数缩放,为 ASC 卷积神经网络创建输入特征。
每1024毫秒,将 (30×32) LogMel声谱图输入到ASC卷积神经网络输入,然后可以将输出标签分类为室内、室外和车内。
传感器
数字MEMS麦克风(参考: MP34DT05-A)
数据
数据格式22h53m的音频样本
结果
模型意法半导体量化卷积神经网络
输入大小:30x32
复杂度517 K MACC
内存占用:
31 KB闪存 ,用于权重
18 KBRAM,用于激活
STM32L476(低功耗)上的性能 @ 80 MHz
用例:1 分类/秒
预/后处理:3.7 MHz
NN 处理:6 MHz
功耗(1.8 V)
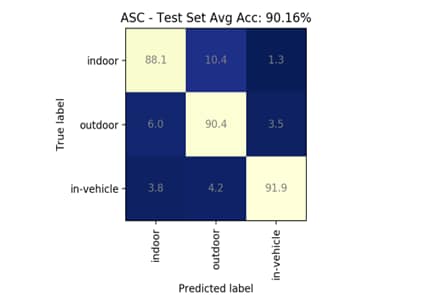
混淆矩阵


资源 ![STM32Cube.AI]()
![STM32Cube.AI]()
![STM32]()
![STM32]()
优化工具 STM32Cube.AI
X-CUBE-AI是一个免费的STM32Cube扩展包,可帮助开发人员将预训练的AI算法(例如神经网络和机器学习模型)自动转换为经过优化的STM32 C代码。
兼容 STM32
STM32系列32位微控制器基于Arm Cortex®-M处理器,旨在为MCU用户提供新的开发自由度。它包括一系列产品,集高性能、实时功能、数字信号处理、低功耗/低电压操作、连接性等特性于一身,同时还保持了集成度高和易于开发的特点。