产品概述
主要优势

Fast, automated edge AI deployment
Converts pretrained NN and classical ML models into optimized C libraries for STM32, reducing manual porting and integration efforts.

Maximized performance and efficiency on STM32
Provides detailed RAM/flash usage and optimizes/schedules operations on the NeuralART NPU (with CPU fallback).

Seamless integration in the STM32Cube ecosystem
Free desktop tool for Windows and Linux, aligned with the STM32Cube ecosystem. Enables easy portability across STM32 series.
描述
STM32Cube AI Studio (STEDGEAI-CUBEAI) 是意法半导体推出的桌面工具,用于评估、优化和编译STM32微控制器的神经网络 (NN) 模型。它还管理Neural-ART加速器神经处理单元 (NPU) 的神经网络模型编译。它取代了意法半导体AI产品线中的X-CUBE-AI,以涵盖新款STM32器件。

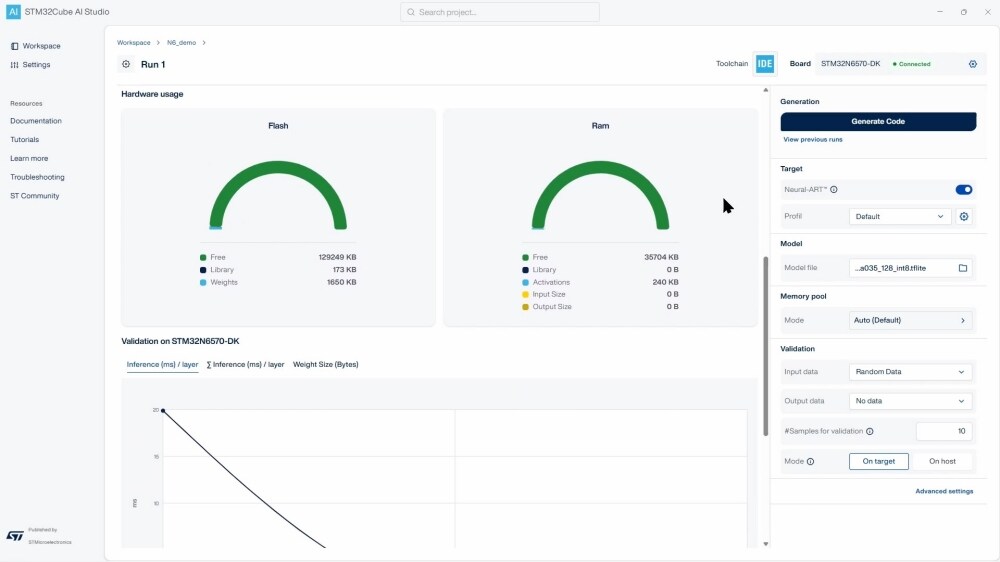
STM32Cube AI Studio是一款免费的GUI,支持将预训练的人工智能算法(包括神经网络 (NN) 和经典机器学习模型 (ML))自动转换为等效优化C代码,以便嵌入应用程序中。生成的优化库为在边缘设备上部署AI提供了一种易于使用且对开发人员友好的方式。针对Neural-ART加速器NPU加速器优化NN模型时,在可能的情况下,工具会生成微代码以将AI操作映射至NPU执行,否则自动回退至CPU处理。
STM32Cube AI Studio采用意法半导体边缘AI内核技术 (CLI),该技术可优化适配所有具备AI功能的意法半导体产品的NN模型。Neural-ART加速器是意法半导体的专有AI加速器,内置于部分产品中,例如STM32N6系列。如果要确认目标产品是否内置Neural-ART加速器,请参见数据手册。
意法半导体边缘AI套件
STM32N6 AI生态系统的所有工具和软件包均属于意法半导体ST Edge AI Suite。该套件整合了多种软件工具,旨在简化嵌入式AI应用的开发和部署。该综合套件支持从数据收集到在硬件最终部署的整个机器学习算法和神经网络模型的优化和部署流程,简化了跨学科领域的专业人士的工作流程。
意法半导体边缘AI套件支持意法半导体的多种产品,包括STM32微控制器和微处理器、Neural-ART加速器、Stellar微控制器以及智能传感器。
作为推动边缘AI技术普及化的战略举措,意法半导体边缘AI套件为希望在嵌入式系统中高效利用AI的开发人员提供了强大的资源。
-
所有功能
- 从预训练神经网络 (NN) 和经典机器学习 (ML) 模型生成STM32优化库
- 提供有关人工智能 (AI) 模型RAM和Flash存储器大小的详细信息
- 根据主机和目标设备上的参考模型验证优化模型
- STM32本地开发板上的基准模型性能
- 支持意法半导体Neural-ART加速器神经处理单元 (NPU),用于硬件加速AI/ML模型
- 原生支持多种深度学习框架,如Keras、TensorFlowTM Lite和LiteRT,同时兼容所有可导出为ONNX标准格式的框架,包括PyTorchTM、MATLAB®等
- 支持通过ONNX使用多种内置的scikit-learn模型,如孤立森林、支持向量机 (SVM) 和K-means等
- 通过STM32Cube生态系统兼容性在不同的STM32微控制器系列之间实现轻松移植
- 免费易用的许可条款
